计算机网络
OSI 与 TCP/IP 各层的结构与功能, 都有哪些协议?
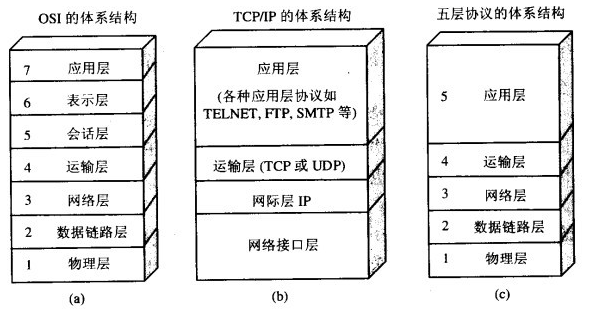
计算机网络体系结构:(a)OSI的七层协议;(b)TCP/IP的四层协议;(c)五层协议
七层体系结构图总结
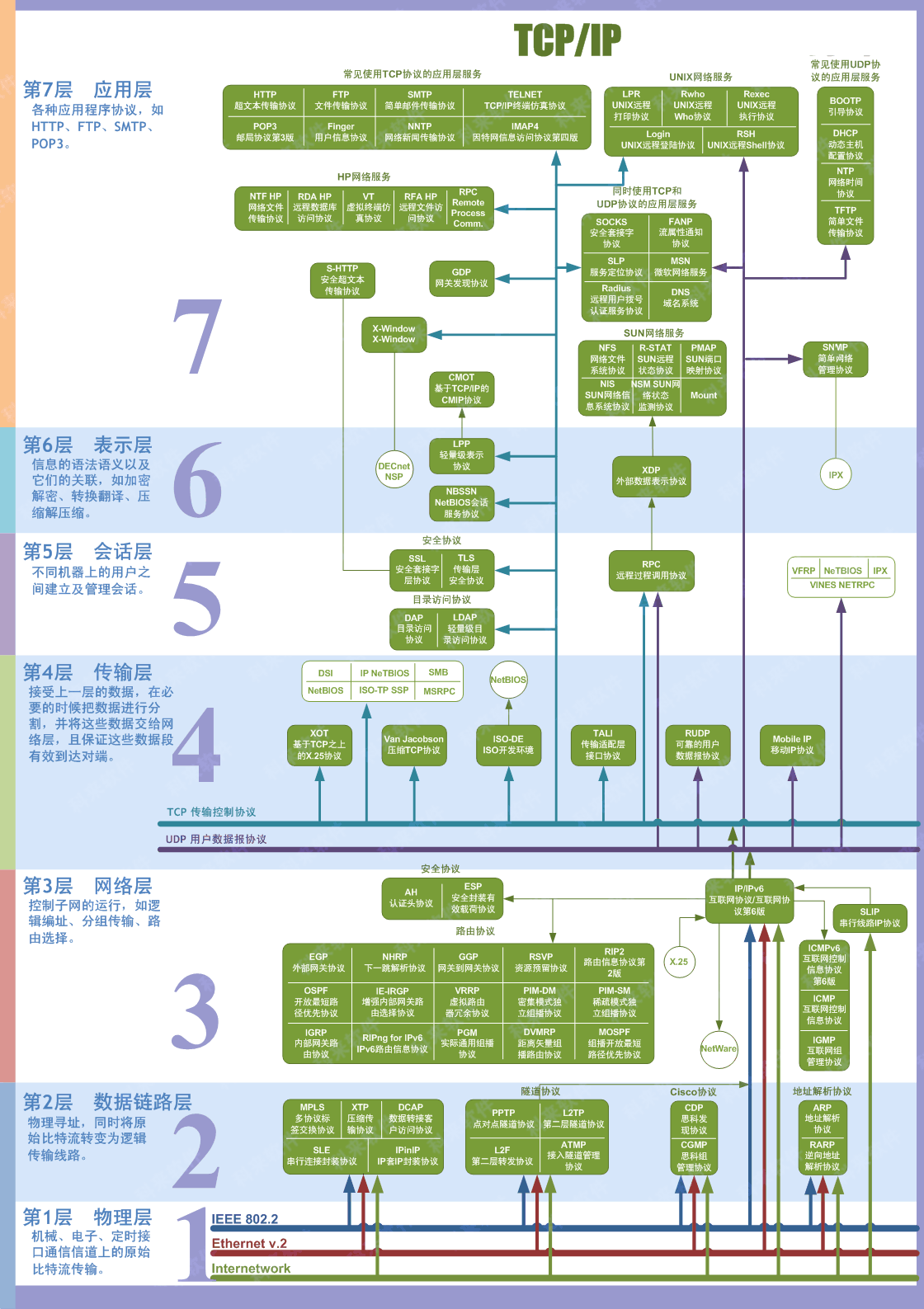
TCP 三次握手和四次挥手
三次握手
- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
为什么要三次握手
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
所以三次握手就能确认双发收发功能都正常,缺一不可。
四次挥手
客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
服务器-关闭与客户端的连接,发送一个 FIN 给客户端
客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
浏览器中输入 url 地址 ->> 显示主页的过程
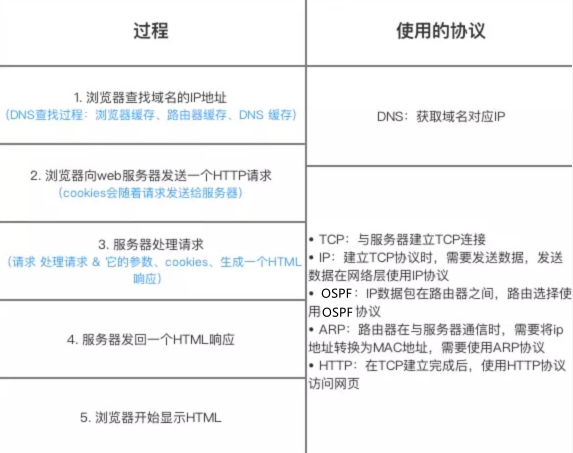
- DNS 解析
- TCP 连接
- 发送 HTTP 请求
- 服务器处理请求并返回 HTTP 报文
- 浏览器解析渲染页面
- 连接结束
数据结构
数组
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
数组的特点是:提供随机访问 并且容量有限。
链表
链表(LinkedList) 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
常见链表分类:
- 单链表
- 双向链表
- 循环链表
- 双向循环链表
应用场景
- 如果需要支持随机访问的话,链表没办法做到。
- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
数组 vs 链表
- 数组支持随机访问,而链表不支持。
- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
- 数组的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
栈
栈 (stack)只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 后进先出(LIFO, Last In First Out) 的原理运作。在栈中,push 和 pop 的操作都发生在栈顶。
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作 链式栈 。
栈的常见应用常见应用场景
当我们我们要处理的数据只涉及在一端插入和删除数据,并且满足 后进先出(LIFO, Last In First Out) 的特性时,我们就可以使用栈这个数据结构。
队列
队列 是 先进先出( FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
单队列
单队列就是常见的队列, 每次添加元素时,都是添加到队尾。单队列又分为 顺序队列(数组实现) 和 链式队列(链表实现)。
顺序队列存在“假溢出”的问题也就是明明有位置却不能添加的情况。
循环队列
循环队列可以解决顺序队列的假溢出和越界问题。解决办法就是:从头开始,这样也就会形成头尾相接的循环,这也就是循环队列名字的由来。
图
顶点
图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)
对应到好友关系图,每一个用户就代表一个顶点。
边
顶点之间的关系用边表示。
对应到好友关系图,两个用户是好友的话,那两者之间就存在一条边。
度
度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。
对应到好友关系图,度就代表了某个人的好友数量。
无向图和有向图
边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A是B的同学,那么B也肯定是A的同学,那么在表示A和B的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A是B的爸爸,但B肯定不是A的爸爸,A关注B,B不一定关注A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
无权图和带权图
对于一个关系,如果我们只关心关系的有无,而不关心关系有多强,那么就可以用无权图表示二者的关系。
对于一个关系,如果我们既关心关系的有无,也关心关系的强度,比如描述地图上两个城市的关系,需要用到距离,那么就用带权图来表示,带权图中的每一条边一个数值表示权值,代表关系的强度。
堆
堆中的每一个节点值都大于等于(或小于等于)子树中所有节点的值。或者说,任意一个节点的值都大于等于(或小于等于)所有子节点的值。
当我们只关心所有数据中的最大值或者最小值,存在多次获取最大值或者最小值,多次插入或删除数据时,就可以使用堆。
- 最大堆 :堆中的每一个节点的值都大于等于子树中所有节点的值
- 最小堆 :堆中的每一个节点的值都小于等于子树中所有节点的值
树
树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
一棵树具有以下特点:
- 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
- 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
- 一棵树不包含回路。
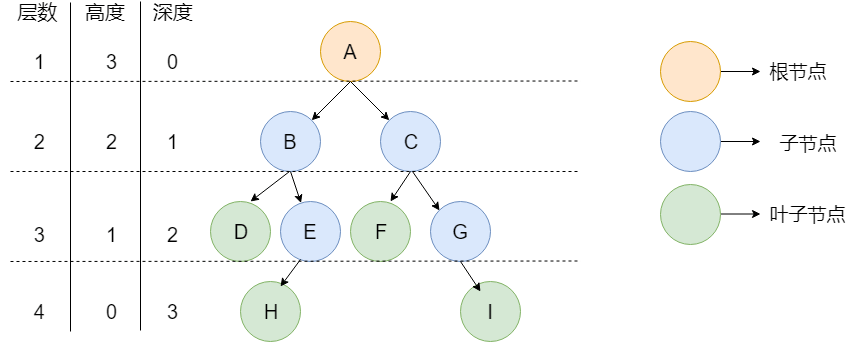
节点 :树中的每个元素都可以统称为节点。
根节点 :顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
父节点 :若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
子节点 :一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
兄弟节点 :具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
叶子节点 :没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
节点的高度 :该节点到叶子节点的最长路径所包含的边数。
节点的深度 :根节点到该节点的路径所包含的边数
节点的层数 :节点的深度+1。
树的高度 :根节点的高度。
布隆过滤器
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
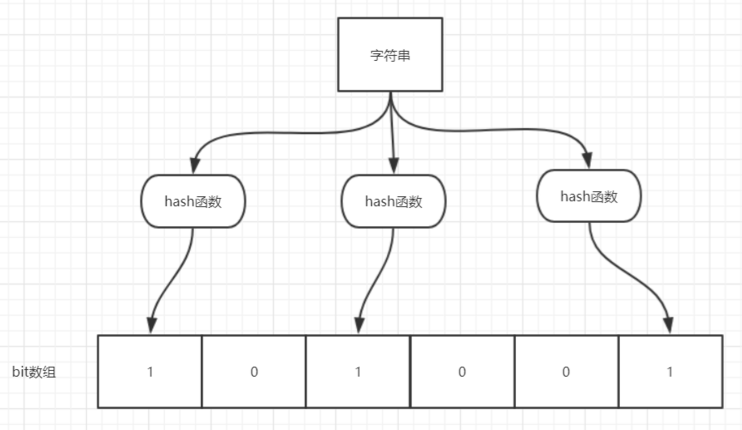
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
布隆过滤器使用场景
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
利用 Google 开源的 Guava 中自带的布隆过滤器
创建了一个最多存放 最多 1500 个整数的布隆过滤器,并且可以容忍误判的概率为百分之(0.01)
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1500,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。
Redis 中的布隆过滤器
Doker安装
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
docker exec -it redis-redisbloom bash
redis-cli
常用命令一览
注意: key : 布隆过滤器的名称,item : 添加的元素。
BF.ADD:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:BF.ADD {key} {item}。BF.MADD: 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式BF.ADD与之相同,只不过它允许多个输入并返回多个值。格式:BF.MADD {key} {item} [item ...]。BF.EXISTS: 确定元素是否在布隆过滤器中存在。格式:BF.EXISTS {key} {item}。BF.MEXISTS: 确定一个或者多个元素是否在布隆过滤器中存在格式:BF.MEXISTS {key} {item} [item ...]。
另外, BF. RESERVE 命令需要单独介绍一下:
这个命令的格式如下:
BF. RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] 。
下面简单介绍一下每个参数的具体含义:
- key:布隆过滤器的名称
- error_rate : 期望的误报率。该值必须介于 0 到 1 之间。例如,对于期望的误报率 0.1%(1000 中为 1),error_rate 应该设置为 0.001。该数字越接近零,则每个项目的内存消耗越大,并且每个操作的 CPU 使用率越高。
- capacity: 过滤器的容量。当实际存储的元素个数超过这个值之后,性能将开始下降。实际的降级将取决于超出限制的程度。随着过滤器元素数量呈指数增长,性能将线性下降。
可选参数:
- expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以
expansion。默认扩展值为 2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。