Python基础
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的
.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8编码。
数据类型
整数
1,-1,0
十六进制: 前面加0x ,如0xff00,0xa5b4c3d2
很大的数:中间可以用_隔开,如10000000000写成10_000_000_000
浮点数
3.14,-9.01
很大或很小的数:
必须用科学计数法表示,把10用e替代,1.23x10^9^就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5
整数运算永远是精确的,而浮点数运算则可能会有四舍五入的误差
字符串
单引号,双引号: 普通字符串
三单引号: 简化\n可以换行
r'' : 表示字符串默认不转义(也可以在三单引号前加r)
编码
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | 01001110 00101101 | 11100100 10111000 10101101 |
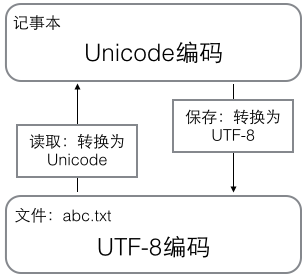
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
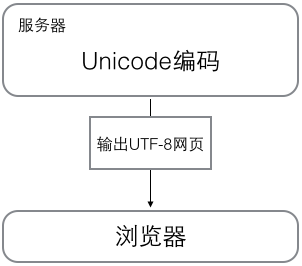
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
# 16进制写法
>>> '\u4e2d\u6587'
'中文'
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
格式化
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
如果只有一个%?,括号可以省略。
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
字符串里面的%是一个普通字符,需要转义,用%%来表示一个%
布尔值
True、False
布尔值可以用and、or和not运算
空值
None
变量
变量名必须是大小写英文、数字和_的组合,且不能用数字开头
常量
PI = 3.14159265359
通常用全部大写的变量名表示常量
除法
/: 普通除法,精确的除法
//: 地板除,只取结果的整数部分
%: 取余
流程控制
**elif是else if**的缩写
age = 3
if age >= 18:
print('adult')
elif age >= 6:
print('teenager')
else:
print('kid')
if判断条件还可以简写,比如写:
if x:
print('True')
只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False。
match语句
score = 'B'
match score:
case 'A':
print('score is A.')
case 'B':
print('score is B.')
case 'C':
print('score is C.')
case _: # _表示匹配到其他任何情况
print('score is ???.')
循环
for
计算1-100的整数之和,Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。range(101)就可以生成0-100的整数序列
sum = 0
for x in range(101):
sum = sum + x
print(sum)
while
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
break、continue和Java中一样
dict
同map,使用键-值(key-value)存储,具有极快的查找速度。
# 定义
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
# 取值
d['Michael']
# 赋值
d['Adam'] = 67
# 判断key是否存在
'Thomas' in d
# 也可以通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
# 删除
d.pop('Bob')
set
和java用法一样
添加: add(key)
删除: remove(key)
函数
函数定义
def my_abs(x):
if x >= 0:
return x
else:
return -x
print(my_abs(-99))
空函数
def nop():
pass
返回多个值
默认参数
定义默认参数要牢记一点:默认参数必须指向不变对象!
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
可变参数
可变参数允许传入0个或任意个参数
def calc(*numbers):
pass
参数前面加个星号
要把list或tuple的元素变成可变参数传进去,只用在前面加个星号
关键字参数
参数前可以加两个星号, 可以传dict
如果是命名关键字参数,可以用星号分隔,参数列表中星号后面的是只接受的关键字参数,如果函数定义中已经有一个可变参数,后面跟着的命名关键字参数就不需要特殊分隔符了.
参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
>>> f1(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> f1(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> f1(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> f1(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
>>> f2(1, 2, d=99, ext=None)
a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
通过一个tuple和dict,调用上述函数:
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
对于任意函数,都可以通过类似
func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
https://liaoxuefeng.com/books/python/introduction/index.html
前7章已经看完了,后面有空再看