elasticsearch环境搭建
docker安装es
# 拉取es
docker pull elasticsearch:7.6.2
# 启动
docker run -d --name es -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" elasticsearch:7.6.2
设置密码
vi config/elasticsearch.yml
#添加如下内容
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
重启,然后进入容器
./bin/elasticsearch-setup-passwords interactive
然后重启即可
安装elasticsearch-head
我这里用的是谷歌浏览器插件插件地址 (opens new window)
docker安装kibana
# 拉取kibana 版本号要和es对应
docker pull kibana:7.6.2
# 启动
docker run -d --name kibana -p 5601:5601 -v /home/es/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.6.2
编写配置文件
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://172.17.0.1:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"
安装ik分词器插件
# 拷贝文件到容器
docker cp /home/es/plugins/ik 70036fb3d3e5:/usr/share/elasticsearch/plugins
# 重新启动
docker restart 70036fb3d3e5
REST风格操作
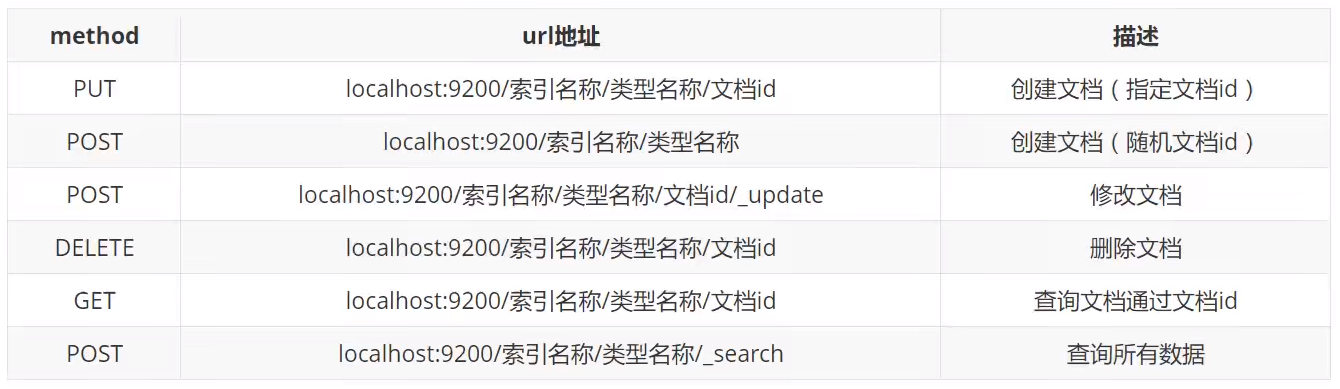
ik分词器
# 会做最粗粒度的拆分
# 中国,人类
GET _analyze
{
"tokenizer": "ik_smart",
"text": "中国人类"
}
# 会将文本做最细粒度的拆分
# 中国人,中国,国人,人类
GET _analyze
{
"tokenizer": "ik_max_word",
"text": "中国人类"
}
es常见查询
term:精准查询
term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇
match:匹配查询
区别:match和term的区别是,match查询的时候,elasticsearch会根据你给定的字段提供合适的分析器,而term查询不会有分析器分析的过程,match查询相当于模糊匹配,只包含其中一部分关键词就行
bool查询
bool查询包含四种操作符,分别是must,should,must_not,query。它们均是一种数组,数组里面是对应的判断条件
- must:必须匹配,与and等价。贡献算分
- must_not:必须不匹配,与not等价,常过滤子句用,但不贡献算分
- should:选择性匹配,至少满足一条,与 OR 等价。贡献算分
- filter:过滤子句,必须匹配,但不贡献算分
filter查询
过滤器,会查询对结果进行缓存,不会计算相关度,避免计算分值,执行速度非常快。
filter也常和range范围查询一起结合使用,range范围可供组合的选项
- gt : 大于
- lt : 小于
- gte : 大于等于
- lte :小于等于
集成springboot
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
改版本
<elasticsearch.version>7.6.2</elasticsearch.version>
增删改查操作
@SpringBootTest
class EsdemoApplicationTests {
private final Logger log = LoggerFactory.getLogger(this.getClass());
@Autowired
private RestHighLevelClient restHighLevelClient;
public final static String ES_INDEX = "test_index";
/**
* api 调用
*/
@Test
public void testCreateIndex() throws IOException {
// 测试索引是否存在
GetIndexRequest getIndexRequest = new GetIndexRequest(ES_INDEX);
boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
log.info("索引是否存在:{}", exists);
if (!exists) {
// 创建索引请求
CreateIndexRequest request = new CreateIndexRequest(ES_INDEX);
// 客户端执行请求
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
log.info("索引创建成功:{}", createIndexResponse);
}
/* 文档操作 */
//创建文档
User user = new User("张三", 7);
IndexRequest index = new IndexRequest(ES_INDEX);
// 规则 put/index/_doc/1
index.id("1");
index.timeout(TimeValue.timeValueSeconds(1));
// 将数据放入请求
index.source(JSONUtil.toJsonStr(user), XContentType.JSON);
// 发送请求 ,获取响应结果
IndexResponse indexResponse = restHighLevelClient.index(index, RequestOptions.DEFAULT);
log.info("响应结果:{},响应状态:{}", indexResponse, indexResponse.status());
// 获取文档
GetRequest getRequest = new GetRequest("test_index", "1");
// 不获取返回的 _source 的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists1 = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
log.info("查看文档是否存在:{}", exists1);
GetRequest getRequest2 = new GetRequest("test_index", "1");
GetResponse documentFields = restHighLevelClient.get(getRequest2, RequestOptions.DEFAULT);
String sourceAsString = documentFields.getSourceAsString();
log.info("文档内容:{}", sourceAsString);
// 更新文档
UpdateRequest updateRequest = new UpdateRequest("test_index", "1");
User user1 = new User("李四", 8);
updateRequest.doc(JSONUtil.toJsonStr(user1), XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("更新文档:{},更新状态:{}", update, update.status());
// 批量操作
BulkRequest test_index = new BulkRequest();
for (int i = 0; i < 20; i++) {
test_index.add(new IndexRequest(ES_INDEX).id(i + 2 + "").source(JSONUtil.toJsonStr(new User(RandomUtil.randomString(8), i + 2)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(test_index, RequestOptions.DEFAULT);
log.info("批量执行失败状态:{}", bulk.hasFailures());
// 查询
SearchRequest searchRequest = new SearchRequest(ES_INDEX);
// 构建搜索
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询对象
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("age", 8);
searchSourceBuilder.query(termQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 结果
log.info("搜索返回结果:{}", JSONUtil.toJsonStr(search.getHits()));
for (SearchHit hit : search.getHits().getHits()) {
log.info("结果:{}", hit.getSourceAsMap());
}
// 删除文档
DeleteRequest deleteRequest = new DeleteRequest("test_index", "1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("删除文档:{},删除状态:{}", delete, delete.status());
// 删除索引
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(ES_INDEX);
AcknowledgedResponse deleteResponse = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
log.info("是否删除成功:{}", deleteResponse.isAcknowledged());
}
}